Indexing
Leek index events into elasticsearch cluster, but how it manages different elasticsearch index for each organisation, for each organization application and for each application environment?
Organisation/Application indices
When a user creates a new leek application, leek starts by creating a new index template for that application. an elasticsearch index template allows leek to define templates that will automatically be applied when new application indices are created. The templates include both settings and mappings and a simple pattern template that controls whether the template should be applied to the new index.
An Index template is considered as a Leek Application, the application name and organisation name will be combined
together as orgname-appname to form the final index template name.
for example when a user with the email john@example.com belonging to organization with domain example.com creates
a new application with the name leek. an Index template will be created with the name example.com-leek.
And when users belonging to the same organization try to list the available organization applications, Leek will only
return applications starting with example.com-*
When creating the index template, Leek will add a metadata to the index template with:
Application owner - the application owner is the email of the user who created the application, this metadata field is useful to control who can perform write actions against the application, like deleting application, purging application and managing triggers.
Creation time - when the application was first created.
API Key - the API key that will be used for Leek agent to fanout celery events to Leek API, this is only used with standalone agents, local agents is using a shared secret between Agent and API and provided as an environment variable.
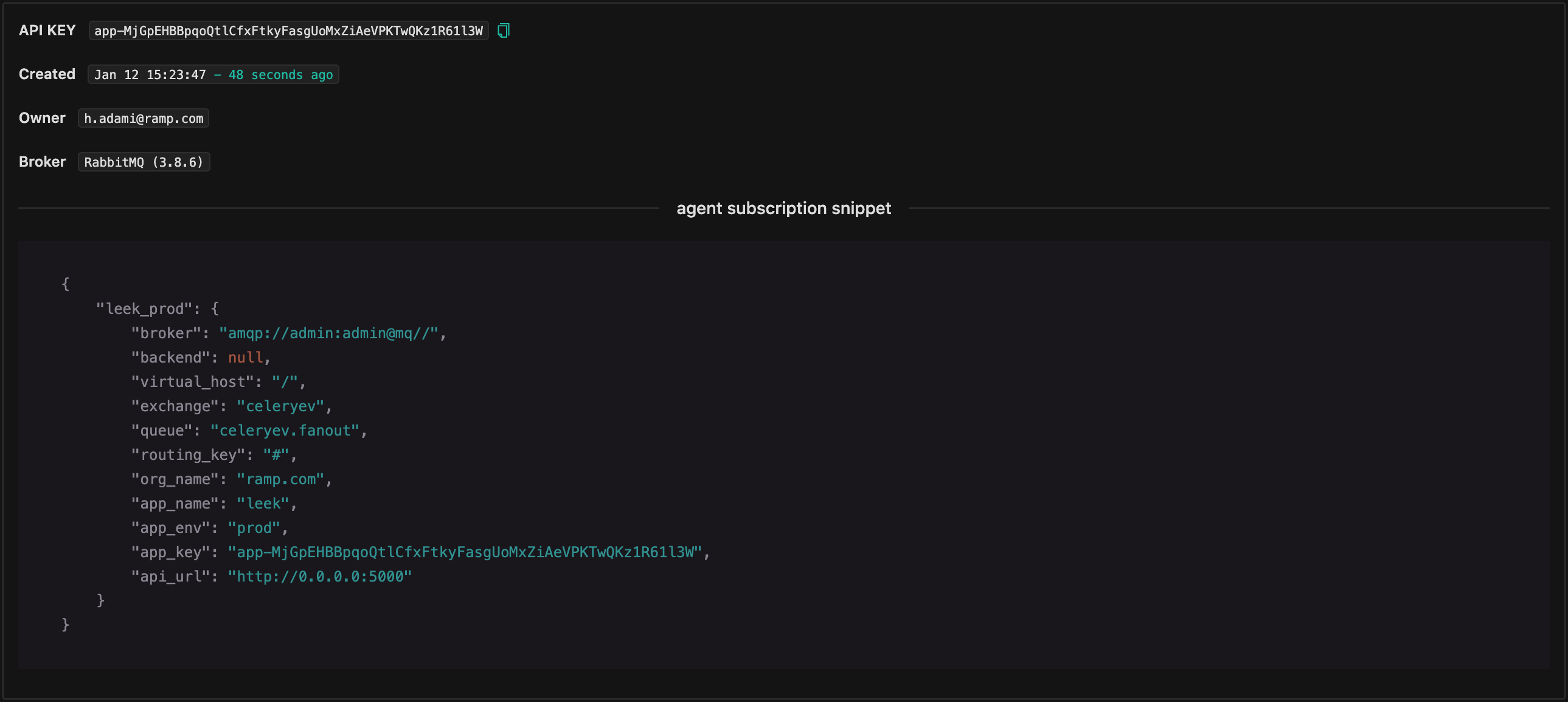
After creating the application (index template), leek will create an initial index with the name orgname-appname-00001
and the index template will automatically be applied to it because it matches the index pattern in the template.

Environment separation
When the mapping is applied to the index, a property named env_name will be used to isolate different events from
different application environments in the same index.
The agent will always send the env_name header enclosed with the request, and Leek will add it to ES document during
the indexation of the events.
Events types separation
The mapping properties include a property named kind and used by leek to separate different kind of events. when the
agent sends tasks events, they will be indexed with kind=task. in the other hand, when the agent sends workers events,
they will be indexed with kind=worker.
Index mapping properties
These are the available tasks and workers properties that leek supports for now:
Index template
This is an example of an index template for the application appname belonging to the organization orgname: